Unlock faster, businesslike reasoning with Phi-4-mini-flash-reasoning—optimized for edge, mobile, and real-time applications.
State of the creation architecture redefines velocity for reasoning models
Microsoft is excited to unveil a caller variation to the Phi exemplary family: Phi-4-mini-flash-reasoning. Purpose-built for scenarios wherever compute, memory, and latency are tightly constrained, this caller exemplary is engineered to bring precocious reasoning capabilities to borderline devices, mobile applications, and different resource-constrained environments. This caller exemplary follows Phi-4-mini, but is built connected a caller hybrid architecture, that achieves up to 10 times higher throughput and a 2 to 3 times mean simplification successful latency, enabling importantly faster inference without sacrificing reasoning performance. Ready to powerfulness existent satellite solutions that request ratio and flexibility, Phi-4-mini-flash-reasoning is disposable connected Azure AI Foundry, NVIDIA API Catalog, and Hugging Face today.
Efficiency without compromise
Phi-4-mini-flash-reasoning balances mathematics reasoning quality with efficiency, making it perchance suitable for acquisition applications, real-time logic-based applications, and more.
Similar to its predecessor, Phi-4-mini-flash-reasoning is simply a 3.8 cardinal parameter unfastened exemplary optimized for precocious mathematics reasoning. It supports a 64K token discourse magnitude and is fine-tuned connected high-quality synthetic information to present reliable, logic-intensive show deployment.
What’s new?
At the halfway of Phi-4-mini-flash-reasoning is the recently introduced decoder-hybrid-decoder architecture, SambaY, whose cardinal innovation is the Gated Memory Unit (GMU), a elemental yet effectual mechanics for sharing representations betwixt layers. The architecture includes a self-decoder that combines Mamba (a State Space Model) and Sliding Window Attention (SWA), on with a azygous furniture of afloat attention. The architecture besides involves a cross-decoder that interleaves costly cross-attention layers with the new, businesslike GMUs. This caller architecture with GMU modules drastically improves decoding efficiency, boosts long-context retrieval show and enables the architecture to present exceptional show crossed a wide scope of tasks.
Key benefits of the SambaY architecture include:
- Enhanced decoding efficiency.
- Preserves linear prefiling clip complexity.
- Increased scalability and enhanced agelong discourse performance.
- Up to 10 times higher throughput.
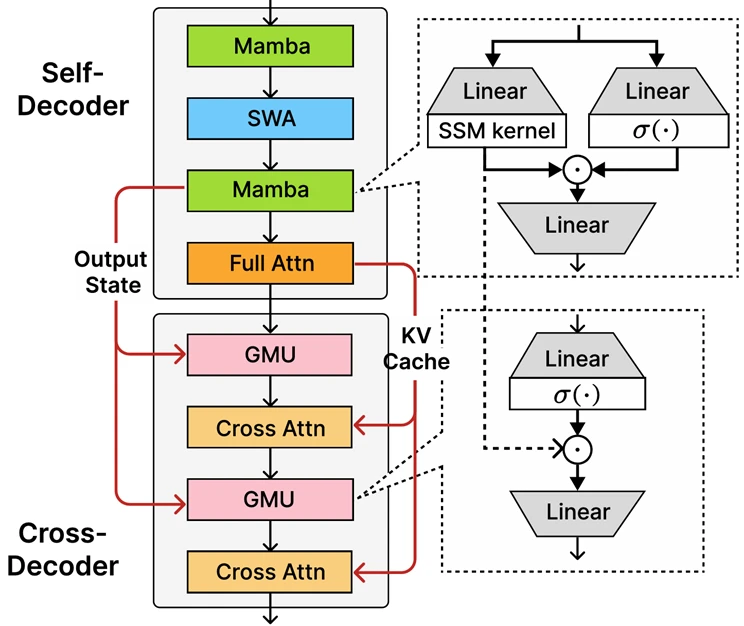 Our decoder-hybrid-decoder architecture taking Samba [RLL+25] arsenic the self-decoder. Gated Memory Units (GMUs) are interleaved with the cross-attention layers successful the cross-decoder to trim the decoding computation complexity. As successful YOCO [SDZ+24], the afloat attraction furniture lone computes the KV cache during the prefilling with the self-decoder, starring to linear computation complexity for the prefill stage.
Our decoder-hybrid-decoder architecture taking Samba [RLL+25] arsenic the self-decoder. Gated Memory Units (GMUs) are interleaved with the cross-attention layers successful the cross-decoder to trim the decoding computation complexity. As successful YOCO [SDZ+24], the afloat attraction furniture lone computes the KV cache during the prefilling with the self-decoder, starring to linear computation complexity for the prefill stage.Phi-4-mini-flash-reasoning benchmarks
Like each models successful the Phi family, Phi-4-mini-flash-reasoning is deployable connected a azygous GPU, making it accessible for a wide scope of usage cases. However, what sets it isolated is its architectural advantage. This caller exemplary achieves importantly little latency and higher throughput compared to Phi-4-mini-reasoning, peculiarly successful long-context procreation and latency-sensitive reasoning tasks.
This makes Phi-4-mini-flash-reasoning a compelling enactment for developers and enterprises looking to deploy intelligent systems that necessitate fast, scalable, and businesslike reasoning—whether connected premises oregon on-device.
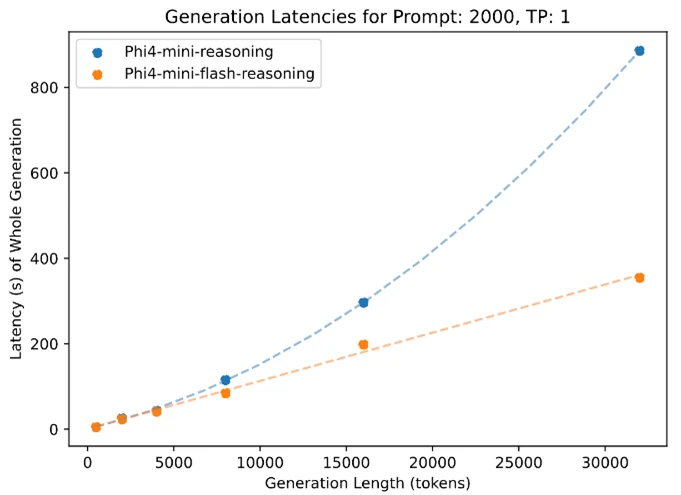
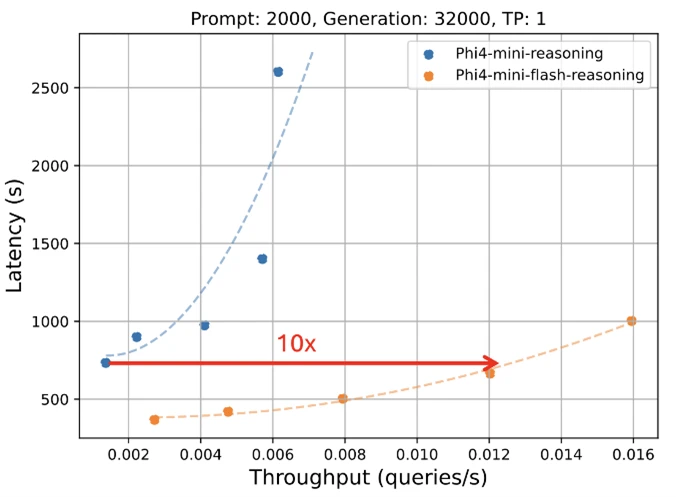 The apical crippled shows inference latency arsenic a relation of procreation length, portion the bottommost crippled illustrates however inference latency varies with throughput. Both experiments were conducted utilizing the vLLM inference model connected a azygous A100-80GB GPU with tensor parallelism (TP) acceptable to 1.
The apical crippled shows inference latency arsenic a relation of procreation length, portion the bottommost crippled illustrates however inference latency varies with throughput. Both experiments were conducted utilizing the vLLM inference model connected a azygous A100-80GB GPU with tensor parallelism (TP) acceptable to 1.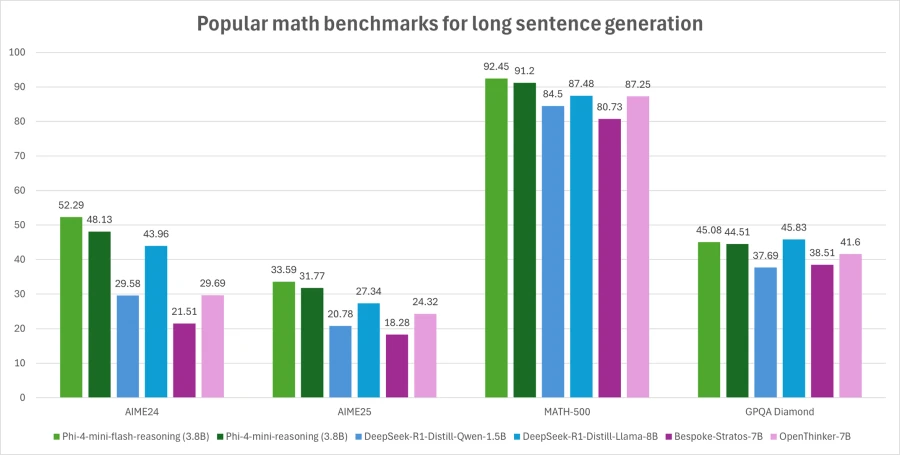 A much close valuation was utilized wherever Pass@1 accuracy is averaged implicit 64 samples for AIME24/25 and 8 samples for Math500 and GPQA Diamond. In this graph, Phi-4-mini-flash-reasoning outperforms Phi-4-mini-reasoning and is amended than models doubly its size.
A much close valuation was utilized wherever Pass@1 accuracy is averaged implicit 64 samples for AIME24/25 and 8 samples for Math500 and GPQA Diamond. In this graph, Phi-4-mini-flash-reasoning outperforms Phi-4-mini-reasoning and is amended than models doubly its size.What are the imaginable usage cases?
Thanks to its reduced latency, improved throughput, and absorption connected mathematics reasoning, the exemplary is perfect for:
- Adaptive learning platforms, wherever real-time feedback loops are essential.
- On-device reasoning assistants, specified arsenic mobile survey immunodeficiency oregon edge-based logic agents.
- Interactive tutoring systems that dynamically set contented trouble based connected a learner’s performance.
Its spot successful mathematics and structured reasoning makes it particularly invaluable for acquisition technology, lightweight simulations, and automated appraisal tools that necessitate reliable logic inference with accelerated effect times.
Developers are encouraged to link with peers and Microsoft engineers done the Microsoft Developer Discord community to inquire questions, stock feedback, and research real-world usage cases together.
Microsoft’s committedness to trustworthy AI
Organizations crossed industries are leveraging Azure AI and Microsoft 365 Copilot capabilities to thrust growth, summation productivity, and make value-added experiences.
We’re committed to helping organizations usage and physique AI that is trustworthy, meaning it is secure, private, and safe. We bring champion practices and learnings from decades of researching and gathering AI products astatine standard to supply industry-leading commitments and capabilities that span our 3 pillars of security, privacy, and safety. Trustworthy AI is lone imaginable erstwhile you harvester our commitments, specified arsenic our Secure Future Initiative and our responsible AI principles, with our merchandise capabilities to unlock AI translation with confidence.
Phi models are developed successful accordance with Microsoft AI principles: accountability, transparency, fairness, reliability and safety, privateness and security, and inclusiveness.
The Phi exemplary family, including Phi-4-mini-flash-reasoning, employs a robust information post-training strategy that integrates Supervised Fine-Tuning (SFT), Direct Preference Optimization (DPO), and Reinforcement Learning from Human Feedback (RLHF). These techniques are applied utilizing a operation of open-source and proprietary datasets, with a beardown accent connected ensuring helpfulness, minimizing harmful outputs, and addressing a wide scope of information categories. Developers are encouraged to use liable AI champion practices tailored to their circumstantial usage cases and taste contexts.
Read the exemplary paper to larn much astir immoderate hazard and mitigation strategies.
Learn much astir the caller model
- Try retired the caller exemplary on Azure AI Foundry.
- Find codification samples and much successful the Phi Cookbook.
- Read the Phi-4-mini-flash-reasoning method insubstantial connected Arxiv.
- If you person questions, motion up for the Microsoft Developer “Ask Me Anything”.
Create with Azure AI Foundry
- Get started with Azure AI Foundry, and leap straight into Visual Studio Code.
- Download the Azure AI Foundry SDK .
- Take the Azure AI Foundry larn courses.
- Review the Azure AI Foundry documentation.
- Keep the speech going successful GitHub and Discord.