Flash enables accelerated detection of issues originating from the Azure platform, helping teams respond rapidly to infrastructure-related disruptions.
Previously, we shared an update connected Project Flash arsenic portion of our Advancing Reliability blog series, reaffirming our committedness to helping Azure customers observe and diagnose virtual instrumentality (VM) availability issues with velocity and precision. This year, we’re excited to unveil the latest innovations that instrumentality VM availability monitoring to the adjacent level—enabling customers to run their workloads connected Azure with adjacent greater confidence. I’ve asked Yingqi (Halley) Ding, Technical Program Manager from the Azure Core Compute team, to locomotion america done the newest investments powering the adjacent signifier of Project Flash.
— Mark Russinovich, CTO, Deputy CISO, and Technical Fellow, Microsoft Azure.Project Flash is simply a cross-division inaugural astatine Microsoft. Its imaginativeness is to present precise telemetry, real-time alerts, and scalable monitoring—all wrong a unified, user-friendly acquisition designed to conscionable the divers observability needs of virtual instrumentality (VM) availability.
Flash addresses some platform-level and user-level challenges. It enables accelerated detection of issues originating from the Azure platform, helping teams respond rapidly to infrastructure-related disruptions. At the aforesaid time, it equips you with actionable insights to diagnose and resoluteness problems wrong your ain environment. This dual capableness supports precocious availability and helps guarantee your concern Service-Level Agreements are consistently met. It’s our ngo to guarantee you can:
- Gain wide visibility into disruptions, specified arsenic VM reboots and restarts, exertion freezes owed to web operator updates, and 30-second big OS updates—with elaborate insights into what happened, wherefore it occurred, and whether it was planned oregon unexpected.
- Analyze trends and acceptable alerts to velocity up debugging and way availability implicit time.
- Monitor astatine standard and physique customized dashboards to enactment connected apical of the wellness of each resources.
- Receive automated basal origin analyses (RCAs) that explicate which VMs were affected, what caused the issue, however agelong it lasted, and what was done to hole it.
- Receive real-time notifications for captious events, specified arsenic degraded nodes requiring VM redeployment, platform-initiated work healing, oregon in-place reboots triggered by hardware issues—empowering your teams to respond swiftly and minimize idiosyncratic impact.
- Adapt betterment policies dynamically to conscionable changing workload needs and concern priorities.
During our team’s travel with Flash, it has garnered wide adoption from immoderate of the world’s starring companies spanning from e-commerce, gaming, finance, hedge funds, and galore different sectors. Their extended utilization of Flash underscores its effectiveness and worth successful gathering the divers needs of high-profile organizations.
At BlackRock, VM reliability is captious to our operations. If a VM is moving connected degraded hardware, we privation to beryllium alerted rapidly truthful we person the maximum accidental to mitigate the contented earlier it impacts users. With Project Flash, we person a assets wellness lawsuit integrated into our alerting processes the infinitesimal an underlying node successful Azure infrastructure is marked unallocatable, typically owed to wellness degradation. Our infrastructure squad past schedules a migration of the affected assets to steadfast hardware astatine an optimal time. This quality to predictively debar abrupt VM failures has reduced our VM interruption complaint and improved the wide reliability of our concern platform.
— Eli Hamburger, Head of Infrastructure Hosting, BlackRock.Suite of solutions disposable today
The Flash inaugural has evolved into a robust, scalable monitoring model designed to conscionable the divers needs of modern infrastructure—whether you’re managing a fistful of VMs oregon operating astatine monolithic scale. Built with reliability astatine its core, Flash empowers you to show what matters most, utilizing the tools and telemetry that align with your architecture and operational model.
Flash publishes VM availability states and resource wellness annotations for elaborate nonaccomplishment attribution and downtime analysis. The usher beneath outlines your options truthful you tin take the close Flash monitoring solution for your scenario.
| Solution | Description |
| Azure Resource Graph (general availability) | For investigations astatine scale, centralized assets repositories, and humanities lookups, you tin periodically devour assets availability telemetry crossed each workloads astatine erstwhile utilizing Azure Resource Graph (ARG). |
| Event Grid strategy topic (public preview) | To trigger time-sensitive and captious mitigations, specified arsenic redeploying oregon restarting VMs to forestall end-user impact, you tin person alerts wrong seconds of captious changes successful assets availability via Event Handlers successful Event Grid. |
| Azure Monitor – Metrics (public preview) | To way trends, aggregate level metrics (e.g., CPU, disk), and configure precise threshold-based alerts, you tin devour an out-of-the-box VM availability metric via Azure Monitor. |
| Resource Health (general availability) | To execute instantaneous and convenient per-resource wellness checks successful the Portal UI, you tin rapidly presumption the RHC blade. You tin besides entree a 30-day humanities presumption of wellness checks for that assets to enactment accelerated and effectual troubleshooting. |
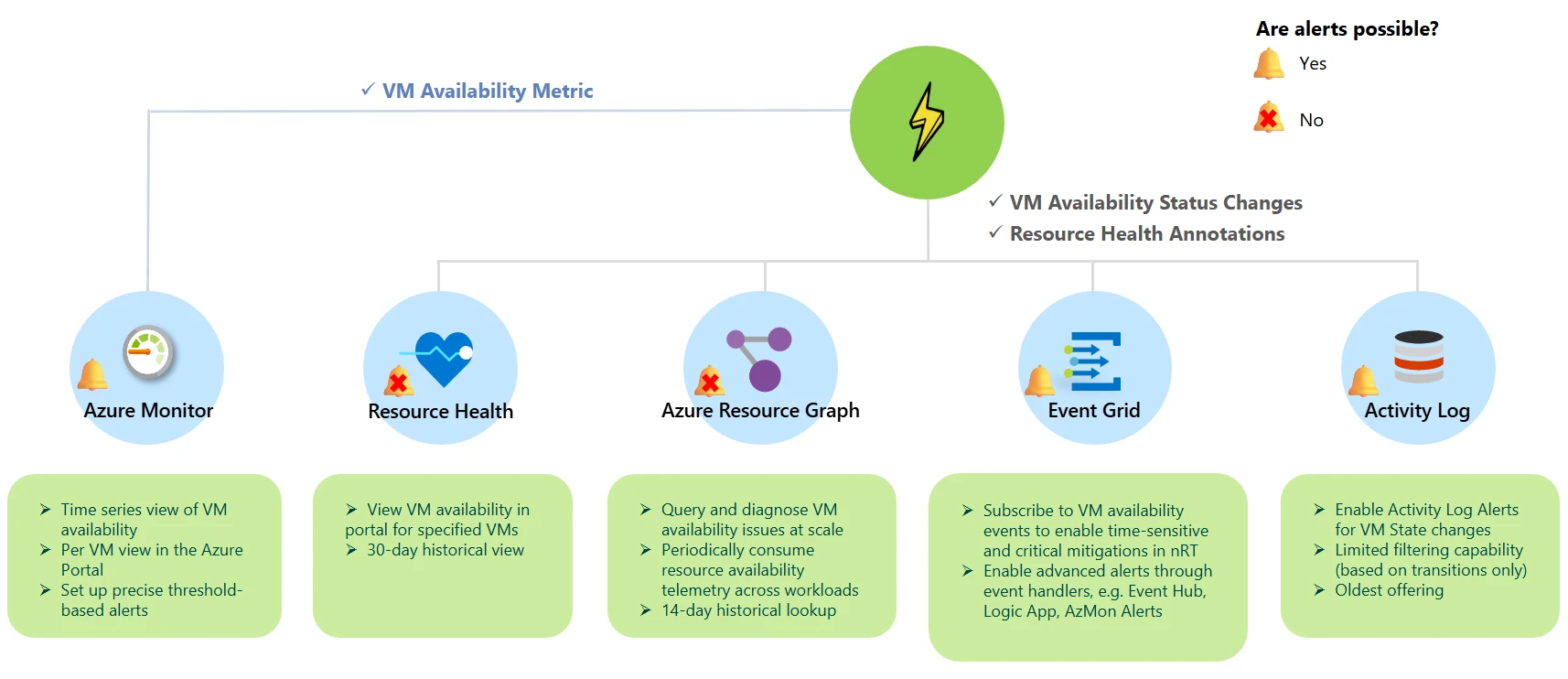 Figure 1: Flash endpoints
Figure 1: Flash endpointsWhat’s new?
Public preview: User vs level magnitude introduced for VM availability metric
Many customers person emphasized the request for user-friendly monitoring solutions that supply real-time, scalable entree to compute assets availability data. This accusation is indispensable for triggering timely mitigation actions successful effect to availability changes.
Designed to fulfill this captious need, the VM availability metric is well-suited for tracking trends, aggregating level metrics (such arsenic CPU and disk usage), and configuring precise threshold-based alerts. You tin utilize this out-of-the-box VM availability metric successful Azure Monitor.
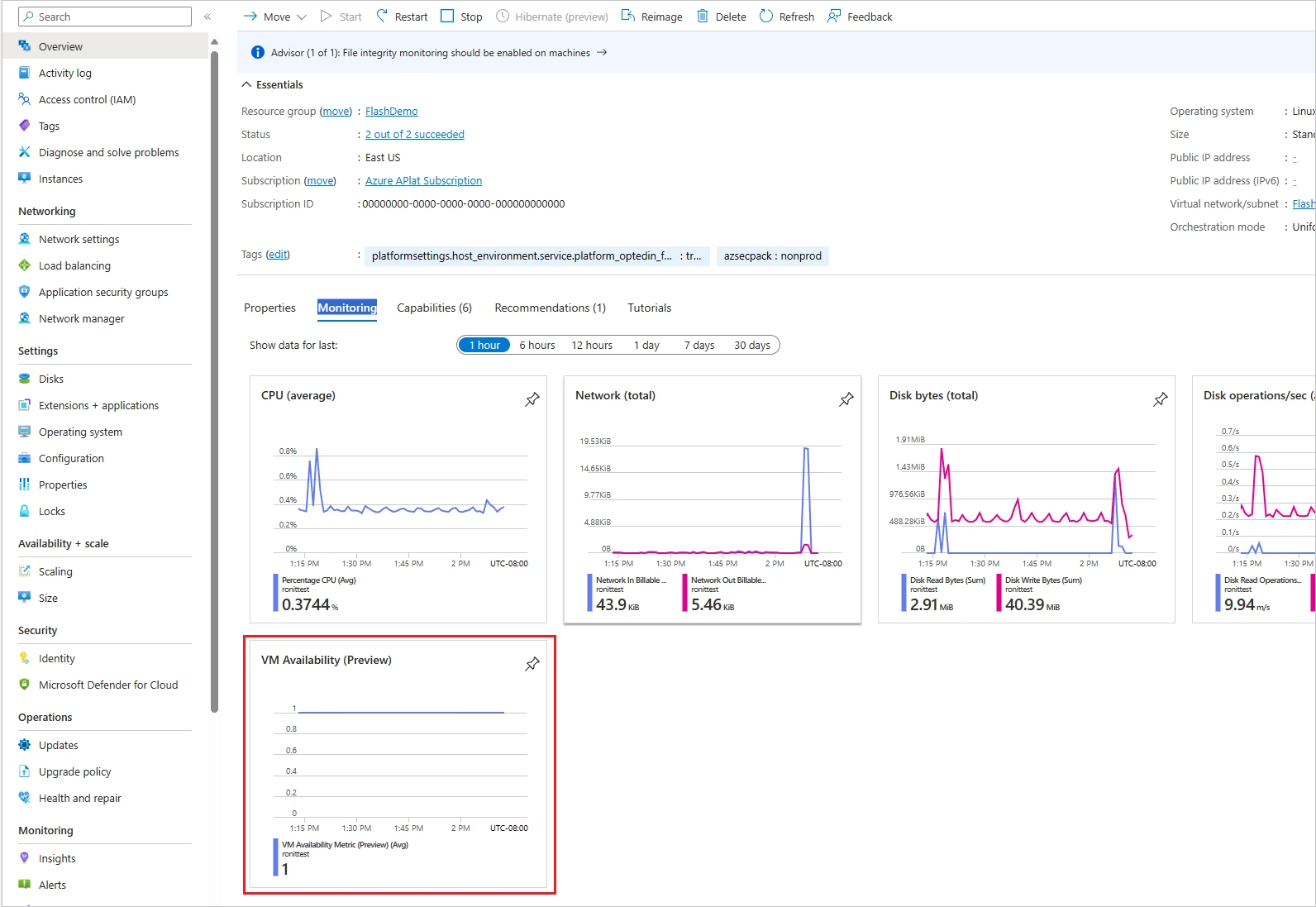 Figure 2: VM availability metric
Figure 2: VM availability metricNow you tin usage the Context dimension to place whether VM availability was influenced by Azure oregon user-orchestrated activity. This magnitude indicates, during immoderate disruption oregon erstwhile the metric drops to zero, whether the origin was platform-triggered oregon user-driven. It tin presume values of Platform, Customer, oregon Unknown.
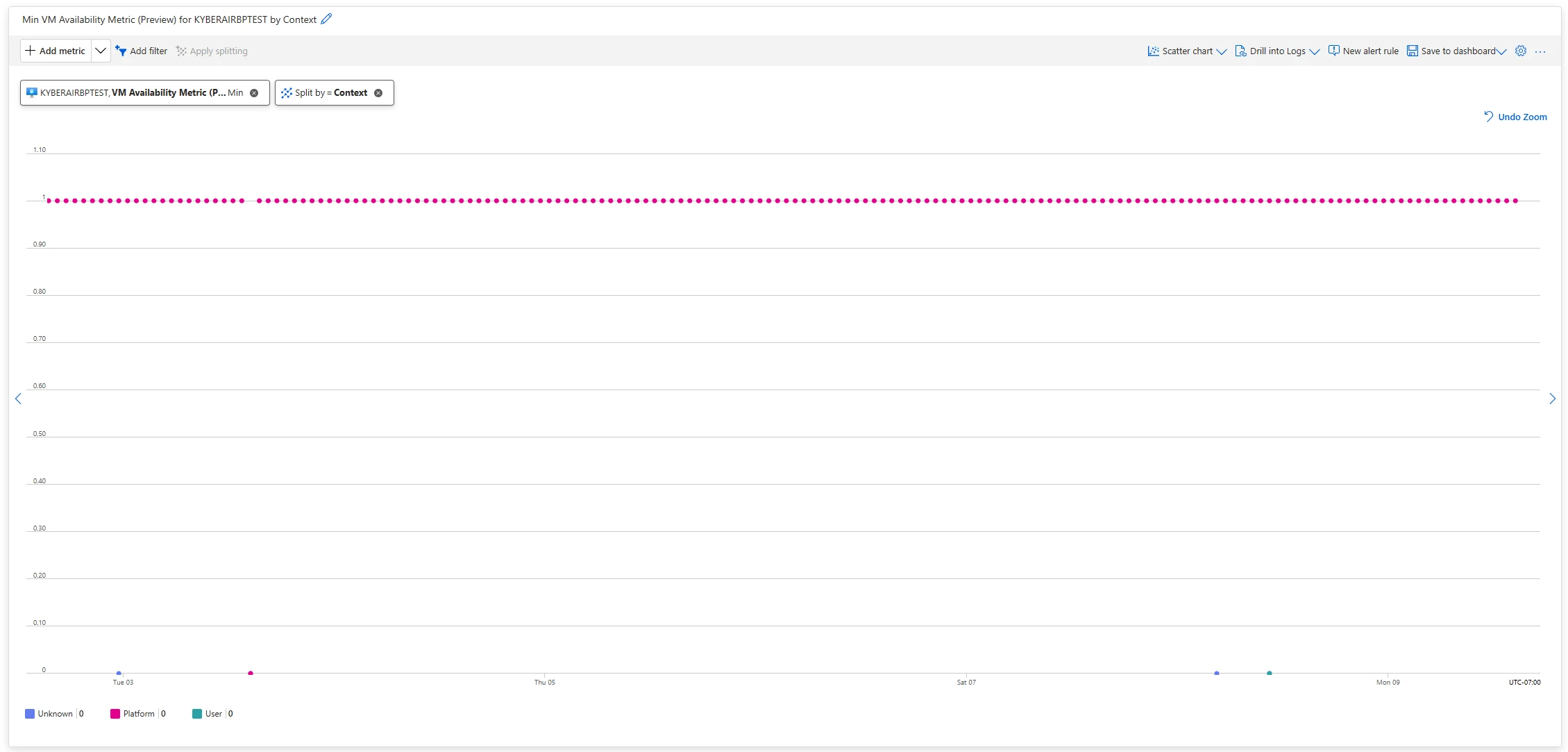 Figure 3: Context dimension
Figure 3: Context dimensionThe caller magnitude is besides supported successful Azure Monitor alert rules arsenic portion of the filtering process.
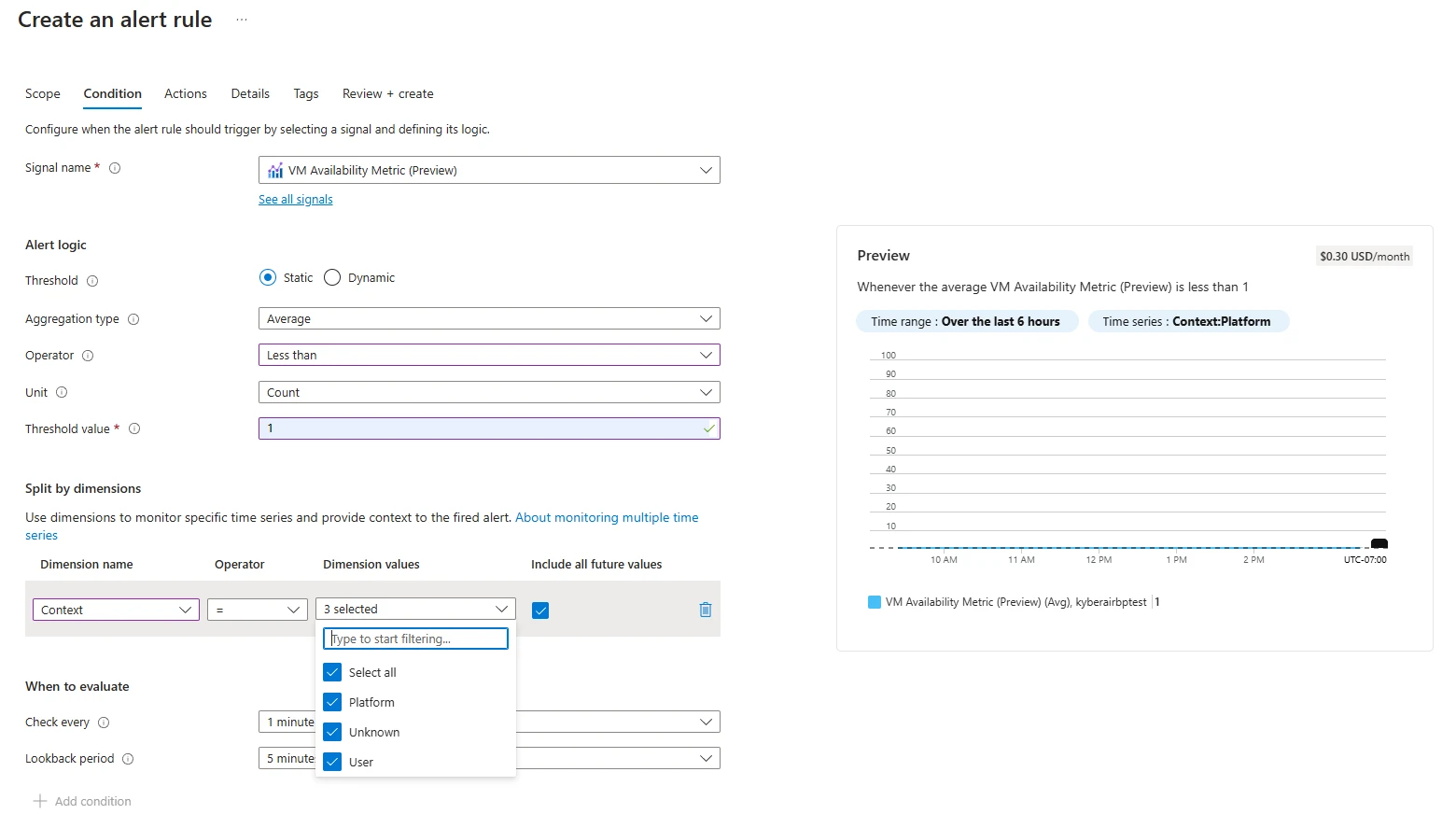 Figure 4: Azure Monitor alert rule
Figure 4: Azure Monitor alert rulePublic preview: Enable sending wellness resources events to Azure Monitor alerts successful Event Grid
Azure Event Grid is simply a highly scalable, afloat managed Pub/Sub connection organisation work that offers flexible connection depletion patterns. Event Grid enables you to people and subscribe to messages to enactment Internet of Things (IoT) solutions. Through HTTP, Event Grid enables you to physique event-driven solutions, wherever a steadfast work (such arsenic Project Flash) announces its strategy authorities changes (events) to subscriber applications.
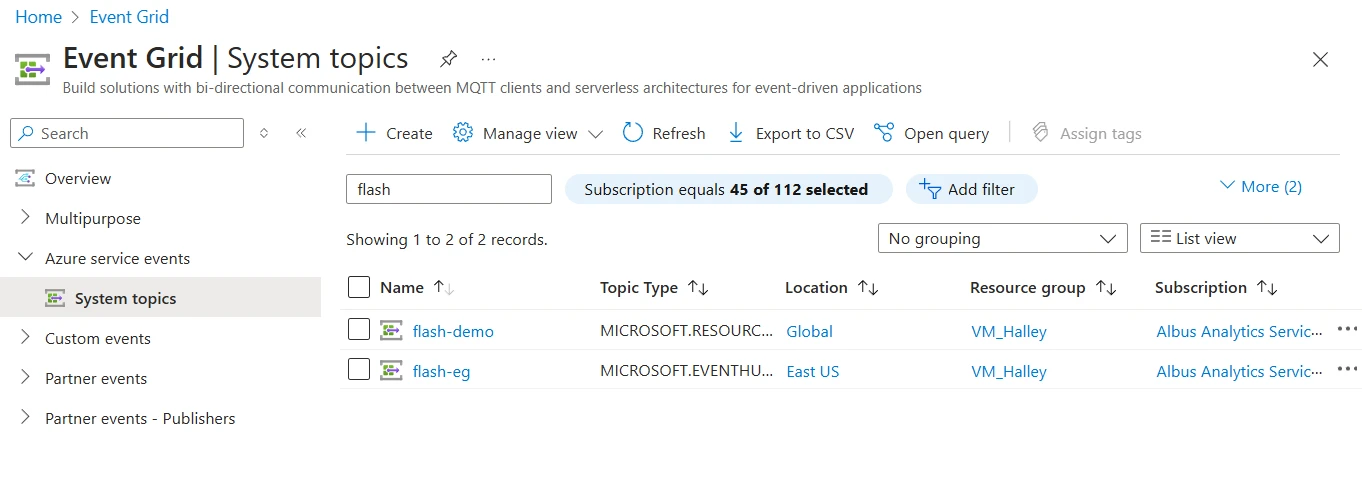 Figure 5: Event Grid strategy topics
Figure 5: Event Grid strategy topicsWith the integration of Azure Monitor alerts arsenic a caller lawsuit handler, you tin present person low-latency notifications—such arsenic VM availability changes and elaborate annotations—via SMS, email, propulsion notifications, and more. This combines Event Grid’s adjacent real-time transportation with Azure Monitor’s nonstop alerting capabilities.
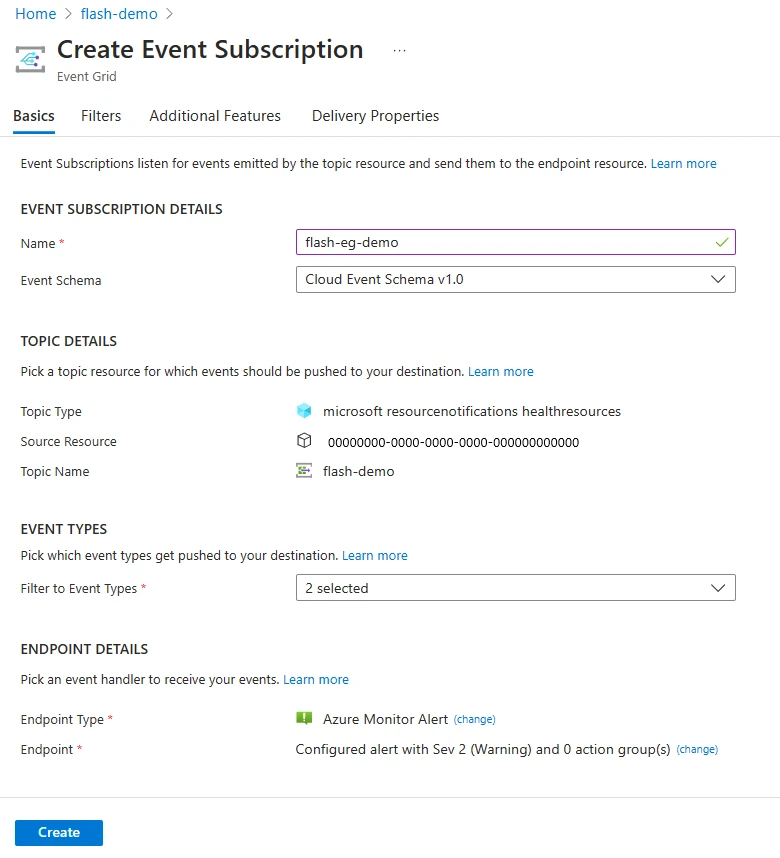 Figure 6: Event Grid subscription
Figure 6: Event Grid subscriptionTo get started, simply travel the step-by-step instructions and statesman receiving real-time alerts with Flash’s caller offering.
What’s next?
Looking ahead, we program to broaden our absorption to see scenarios specified arsenic inoperable top-of-rack switches, failures successful accelerated networking, and caller classes of hardware nonaccomplishment prediction. In addition, we purpose to proceed enhancing information prime and consistency crossed each Flash endpoints—enabling much close downtime attribution and deeper visibility into VM availability.
For broad monitoring of VM availability—including scenarios specified arsenic regular maintenance, unrecorded migration, work healing, and degradation—we urge leveraging some Flash Health events and Scheduled Events (SE).
- Flash Health events connection real-time insights into ongoing and humanities availability disruptions, including VM degradation. This facilitates effectual downtime management, supports automated mitigation strategies, and enhances basal origin analysis.
- Scheduled Events, successful contrast, supply up to 15 minutes of beforehand announcement anterior to planned maintenance, enabling proactive decision-making and preparation. During this window, you whitethorn take to admit the lawsuit oregon defer actions based connected your operational readiness.
For upcoming updates connected the Flash initiative, we promote you to travel the advancing reliability series!